Créer une bonne infrastructure cloud, brique par brique
23h, veille du Black Friday.
Votre site d’e-commerce est prêt à encaisser des milliers de commandes.
Soudain… Error 503. Le serveur surchauffe, la base s’étouffe, les clients s’énervent.
En 10 minutes, votre chiffre d’affaires prend l’eau… et votre réputation aussi.
Pourtant, vous aviez suivi les conseils : scalabilité, haute dispo, multi-région... tous ces buzzwords qu’on vous a vendus comme une armure invincible.
Mais soyons honnêtes : Empiler des technologies sans comprendre pourquoi, ça ne protège de rien.
Et comme “le cloud” est censé tout faire tout seul, on se dit que le problème est réglé.
Sauf que non.
Le cloud ne fait pas le travail à votre place.
👉 Ce qui compte, ce n’est pas où on héberge (bon… un peu quand même 😏), mais comment on construit. Et c’est là que de nombreux projets échouent :
- Soit on surpaye des outils inutiles "au cas où"
- Soit on sous-estime les risques jusqu’au crash
Alors aujourd’hui, je vous propose de reprendre tout depuis le début. Feuille blanche.
Objectif : construire une infrastructure qui tient la route.
Pas un schéma brillant pour une keynote, mais juste un socle technique capable d’encaisser le réel : des utilisateurs, de la charge, des bugs… et des week-ends !
Notre fil rouge ?
🧽 Un e-commerce d’éponges miracles (Ma foi, pourquoi pas ?).
Le site fonctionne, les premiers clients sont là… et tout devient plus sérieux !
Bref, pas de jargon, pas de recette magique.
Juste des choix raisonnés, concrets et expliqués !
C’est parti !
Etape 1 : le serveur
Notre éponge miracle mérite-t-elle un serveur de looser ?
Tout est prêt : le site, le panier, les produits… Mais si vous hébergez ça sur votre PC perso, vous jouez aux dés avec votre business. Explications."
Bon, on veut vendre nos éponges miracles. Le site est prêt, le panier fonctionne, les fiches produits brillent.
Et la déja premiere question : Où est-ce qu’on va faire tourner tout ça ?
Est-ce qu’on peut le lancer depuis son propre ordinateur ?
Techniquement, oui. Est-ce que c'est une bonne idée … non.
Un ordinateur, c’est déjà un serveur. Il peut très bien héberger un site web. On ouvre les bons ports, on lance le site… et hop, en ligne !
Mais il y a un petit détail a ne pas oublier … Quand l’ordinateur s’éteint… le site aussi.
Et s’il y a une mise à jour, une coupure de courant, une perte de connexion, ou si je referme juste mon PC pour aller manger … le site devient inaccessible.
Pas très vendeur pour un e-commerce.
Alors c’est quoi, un “vrai” serveur ?
Un vrai serveur, c’est simplement un ordinateur conçu pour rester allumé tout le temps. 24/7.
Il est souvent placé dans un datacenter, c’est-à-dire un grand bâtiment sécurisé, refroidi, connecté à Internet en permanence, avec des générateurs en cas de coupure.
Un serveur, c’est :
- des processeurs (CPU)
- de la mémoire vive (RAM)
- du stockage (HDD ou SSD)
👉 Comme sur notre PC. Mais conçu pour encaisser des charges, pas pour faire tourner Excel.
Bon du coup qu'est-ce que met sur notre serveur.
Pour commencer ? Tout.
Au début, c’est souvent ça :
On installe l’application web, la base de données, les fichiers, les images, le moteur de paiement, les scripts d’analyse… bref, tout ce qu’il faut pour que ça tourne.
Et honnêtement, ça tourne !
Du moins, tant qu’il n’y a pas trop de monde.
Mais à force de tout concentrer sur une seule machine, on crée un problème : tout devient dépendant de tout.
Si le serveur s'arrete, tout s'arrete, si l’appli rame, la base rame aussi, et si quelqu’un tente une attaque… tout est au même endroit. (les oeufs, le panier …)
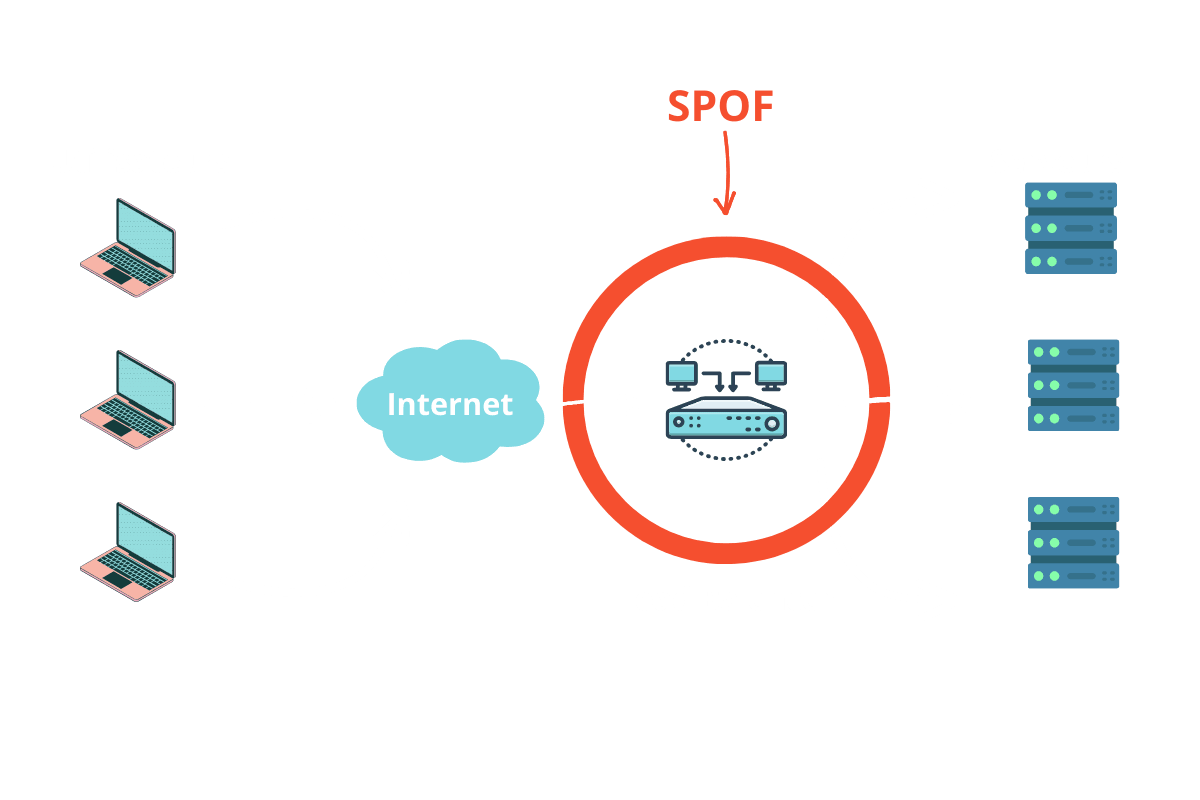
C’est ce qu’on appelle un point de défaillance unique (ou SPOF pour single point of failure). Et ca c’est un piège classique !
Quand Jean-Michel, fidèle client de nos éponges miracle, ne peut pas valider son panier à 23h à cause d’un serveur down… c’est une vente perdue. Et si c’était 1000 Jean-Michel pendant le Black Friday ? Là, ça devient une hémorragie
Et si je prenais un serveur plus puissant ?
C'est un reflexe assez logique : c’est ce qu’on appelle faire du scaling vertical :
On prend une machine plus grosse, avec plus de cœur, plus de RAM, un SSD plus rapide.
Ça marche mieux, c’est vrai.
Mais ça coûte vite très cher. Et surtout : ça ne règle pas le problème de fond.
Car tot ou tard, on atteindra les limites physiques du serveur (CPU, RAM, Stockage)..
Et encore et toujours : si cette machine tombe, aussi surpuissante soit elle : elle est toujours seule.
Car même dopée aux hormones, une machine seule reste une machine seule.
On passe à la suite, on va voir comment séparer les rôles, à commencer par le plus classique :
l’application d’un côté, la base de données de l’autre.
Séparer l’application et la base de données : la première bonne décision
Bon, notre site tourne.
Tout est installé sur un seul et même serveur, et techniquement, ça fonctionne.
Mais on commence à voir les premières limites.
Sur cette machine, deux éléments consomment presque tout :
🧠 L’application web : celle qui affiche les pages, gère les paniers, traite les clics.
📦 La base de données : celle qui stocke les utilisateurs, les commandes, les produits, les stocks.
Et concrètement, ces deux-là sont en train de se marcher dessus.
Mais regardons ce qu'il se passe sous le capot :
Quand un client consulte un produit, le "site internet" doit :
- charger la page
- récupérer les infos en base
- afficher les images
- gérer la navigation
De l'autre coté, la base de données doit :
- répondre à la requête
- enregistrer la commande
- mettre à jour le stock
Sauf que tout ça se passe sur la même machine avec le même CPU, la même RAM, le même disque… Si on se limite a quelque client par jour, il n'y a pas a s'inquieter, ca tournera, mais si 1000 personnes font la meme requete ..
Alors, on respire un grand coup.
Et on prend une première vraie décision d’architecture :
On va séparer l’application et la base de données.
Deux machines, deux rôles.
Un serveur pour l’application web et un serveur pour la base de données
Pourquoi c'est important ?
Parce que chacun va pouvoir travailler sans gêner l’autre.
… Mais c'est surtout ce qui permetra ensuite de scaler chaque partie de manière indépendante. Et c'est surtout ca qui va nous permettre de pouvoir servir un plus grand nombre de demandeurs d'éponge !
Les accès disques ne se marcheront plus dessus. C’est plus clair, plus stable, plus facile à surveiller.
Mais bien evidemment ca complique un peu les choses : Il faut faire communiquer les deux serveurs, sécuriser les accès, configurer le firewall, vérifier les performances réseau…
Mais c’est le premier vrai pas vers une infrastructure propre ! C’est comme passer d’un studio étudiant à un vrai appartement
L’application rame ? Il est temps de la dupliquer !
Bon on avance bien ! Les éponges miracles se vendent bien. Trop bien, même.
Nos éponges passent sur M6, s'empare des reseaux sociaux. CA Y EST NOTRE EPONGE EST VIRALE !
Les clients affluent, les commandes pleuvent, le site chauffe. Que de bonnes nouvelles ! Ou pas
Parce que malgré notre effort pour séparer l’app de la base de données… ça rame encore.
Alors on fait quoi ?
Jusqu’ici, on faisait du scaling vertical.
On prenait un serveur de plus en plus costaud :
plus de CPU, plus de RAM, plus de tout.
Mais ça a ses limites techniques (on ne peut pas dépasser ce que la machine permet) mais aussi économiques (les grosses machines coûtent très cher) …
Donc on va changer de stratégie. On va passer au Scalling horizontal
L’idée est simple :
Au lieu de faire tourner l’application sur une seule grosse machine… …on va la fait tourner sur plusieurs petites machines.
On duplique le code, on déploie l’application sur plusieurs serveurs, et chacun peut gérer une partie du trafic du site.
Pour prendre un exemple bete : c’est comme avoir plusieurs caisses dans un supermarché : plutôt qu’un seul caissier rapide et cher, on met 5 caissiers normaux, et chacun traite un client à la fois.
Pourquoi redondér l’application et pas la base de données ?
Très bonne question !
Parce que dans beaucoup de cas, l’app devient le goulot d’étranglement. Et autant dire que l'application transpirera avant la base.
Mais aussi et surtout parce contrairement à l’application, la BDD (Base De Données) doit garder une cohérence absolue. Mais rassurez-vous, il existe des solutions – réplication, clusters… on verra ca un peu plus tard !
Du coup on se retrouve avec imaginons 5 serveurs avec mon application web :
app1.monepongemagique.com
app2.monepongemagique.com
app3.monepongemagique.com
…
Mais comment faire pour répartir les visiteurs entre tous ces serveurs ? C’est là qu’entre en scène… le load balancer.
Le Load-Balancer
Le répartiteur de charge (ou load balancer pour les intimes), c’est l’agent de circulation qui va s'occuper de notre site.
C’est lui qui reçoit toutes les requêtes entrantes et qui va décider de les rediriger vers le bon serveur.
Il existe plusieurs façons de le rediriger :
Round Robin : on répartit les requêtes 1, 2, 3, 1, 2, 3…
Pondération : certains serveurs prennent plus de requêtes que d’autres
Sticky sessions : un utilisateur reste toujours sur le même serveur
Le load balancer devient donc le point d’entrée de l’infrastructure ! pour etre hyper simple, son travail se limite a :
👉 “Une requête ? Ok, toi tu vas là.”
👉 “La suivante ? Hop, à gauche.”
Là où un serveur applicatif doit traiter la logique métier, afficher une page, enregistrer une commande, echanger avec la base de données… Le load balancer n’a rien à faire de tout ça.
Il redirige et c'est tout.
Est-ce que ça suffit ?
Malheuresement : pas tout à fait.
Parce que maintenant… le load balancer est devenu un SPOF.
S’il tombe, plus rien ne passe.
Peu importe qu’on ait 10 serveurs d’application derrière : plus personne ne pourra y accéder.
Pour éviter que le load balancer ne devienne un SPOF, on utilise une paire active/passive : un deuxième Load Balancer en veille, prêt à prendre le relais en 2 secondes si le premier lâche.
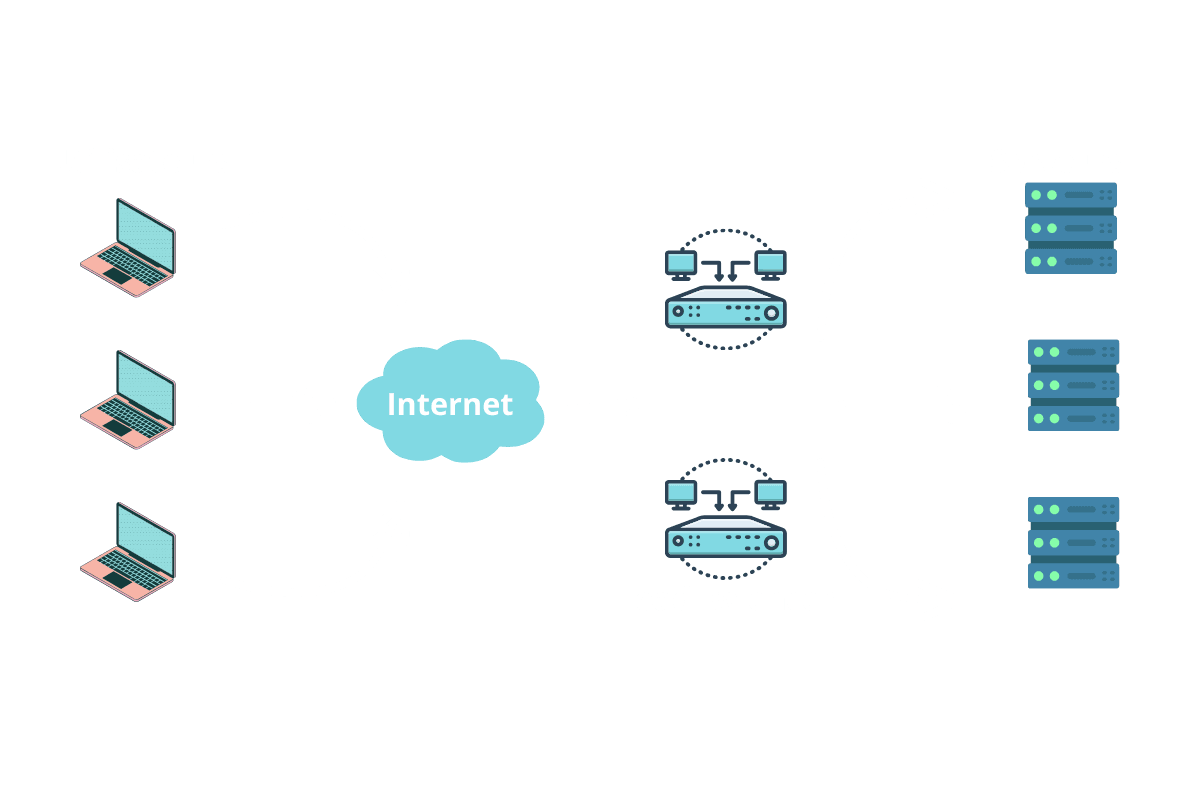
Bon on avance bien ! Maintenant qu’on a un LB redondé et des serveurs d’application élastiques… la base de données commence à tirer la langue. Prochaine étape : lui offrir un coup de jeune avec la réplication Master-Slave. Spoiler : ça implique des clones, des sauvegardes en temps réel… et pas de downtime !
C'est top ! On a une belle infrastrcuture, on peut scaller, rajouter des serveurs en fonction de la demande … Mais … on a oublier quelque chose … Mais maintenant qu’on a du trafic, des utilisateurs actifs, des commandes qui pleuvent, un autre composant commence à tirer la langue !
La base de données : robuste, mais pas immortelle
Bon ! Notre site tourne bien, les serveurs applicatifs sont répliqués, le load balancer fait son travail…
Mais victime de notre succès, un autre maillon commence à fatiguer :
👉 la base de données.
Et là, mauvaise nouvelle : ce n’est pas aussi simple à scaler que le reste.
Bon déja essayons de comprendre a quoi elle nous sert.
Une base de données, c’est comme un carnet ultra-précieux
C’est elle qui garde toute vos informations essentielles : les produits, les utilisateurs, les commandes, les paiements, les stocks…
Parce que oui, on pourrai se dire, beh on va faire comme les serveurs, on va les dupliquer, rajotuer plus de serveur … sauf que contrairement à l’application, elle ne se duplique pas aussi facilement.
Parce que la base, elle doit savoir où est la “vraie” information !
Le vrai problème ? C’est qu’elle est “stateful”
Pour ne rien vous cacher : Stateless = Pas de mémoire des interactions passées (comme un serveur web qui oublie tout après avoir affiché la page).
Stateful = Mémoire critique (la BDD doit se souvenir de chaque commande, sinon adieu le stock !)
Contrairement à une application web qu’on peut dupliquer sans trop de conséquences, la base de données, elle doit être exacte, à tout moment.
On ne peut pas avoir 3 bases différentes avec 3 réponses différentes à la question “combien reste-t-il d’éponges ?” on ne peut pas écrire un peu ici, un peu là, et espérer que tout s’aligne
Quand on fait tourner une app sur plusieurs serveurs, ce n’est pas très grave si l’un tombe : l’autre peut reprendre la charge et afficher le meme contenu.
Mais la base de données… C’est souvent le maillon qui tombe en dernier, mais le probleme, c'est quand il tombe, il emmène tout avec lui.
Et non, je vous vois venir. On ne peut pas avoir deux bases séparées qui disent : BBD 1 : “Stock = 12” | BDD 2 : “Stock = 7”, on comprend vite pourquoi : au premier conflit, c’est le chaos : commandes perdues, données corrompues, clients mécontents… bref la panade !
Parce que contrairement au serveur applicatif qui est stateless, la base de données a besoin de se connecter a tous les serveurs pour pouvoir ecrire l'information.
Et donc non, ajouter des bases ne résout pas le problème de charge.
Ça apporte de la redondance, oui. Mais pas plus de capacité.
Mais alors comment on fait pour scaller notre base ?
L'idée, c'est de garder une base principale (appelée master) qui gère les écritures.
Et on crée une ou plusieurs copies, synchronisées en temps réel ou quasi, qui ne font que de la lecture.
Quand un utilisateur consulte un produit, c’est une replica qui répond.
Quand il passe commande, c’est la base principale qui l’enregistre.
Quand la base master tombe, on peut basculer vers une replica temporairement (si bien configuré).
C'est une premiere solution,
sinon on peut aussi faire du Sharding : on va découper la base en plusieurs morceau (merci pour la traduction Vincent)
- les produits sur une base
- les utilisateurs sur une autre
- les commandes sur une troisième
Chaque shard est ici indépendant, ce qui permet de répartir la charge sur notre BDD, mais ça demande une vraie gestion d’architecture derreire car l’application doit savoir où aller chercher l’information dont elle a besoin ! Mais l'avantage c'est que les bases de données n'ont pas besoin de discuter entre elle, chacune est indépendante.
Halllelujah ! On peut donc désormais scaller nos bases de données !
Bon pour reprendre parce que j'ai peur d'en avoir perdu certain :
- La base de données, c’est un cœur fragile.
- On ne la scale pas comme une app.
- Il faut l’aider à respirer, mais surtout éviter de la fragmenter n’importe comment.
En lecture ? Facile à scaler.
En écriture ? À manier avec précaution.
En cas de très forte charge ? Le sharding devient une obligation … mais à maîtriser.
Et maintenant qu’on a une base (presque) prête pour l’échelle,
on va parler de ce qu’on oublie toujours… jusqu’à ce que ça casse.
Supervision, sauvegardes, PRA, redondance géographique : le nerf de la paix.
Tout est en place.
Nos serveurs éponge sont solides, l’application est répliquée, le trafic est réparti, la base de données tient le coup.
Mais un jour, il se passe un truc bête :
- une coupure de courant
- une panne réseau
- une mise à jour foireuse
- une erreur humaine …
Et là, on réalise qu’on a oublié un truc vital : la résilience.
Supervision, alertes, sauvegardes, PRA…
On n’en parle jamais au début. Parce que tant que tout marche, ça semble secondaire.
Mais le jour où tout plante…
c’est ce qui fait la différence entre une boîte qui panique
et une boîte qui redémarre en 20 minutes.
Quelques incontournables :
un système de monitoring (CPU, RAM, erreurs, lenteurs)
des alertes en cas de problème (pas juste “surveillance passive”)
des sauvegardes automatiques, testées, stockées ailleurs
un plan de reprise (PRA) : que faire si tout s’effondre ?
Et surtout :
➡️ des tests réguliers. Parce qu’un PRA qui n’a jamais été testé… n’est pas un PRA.
Et maintenant ? On l’héberge où, tout ça ?
L’infra est prête.
Elle est bien pensée, bien découpée, et capable de grandir.
Mais une dernière question reste ouverte :
Où est-ce qu’on héberge tout ça ?
Chez soi, dans un placard à serveurs ? Pourquoi pas. Mais… non.
Sur un cloud américain avec 200 options par clic ? Peut-être. Mais bon courage pour comprendre la facture.
Ou alors…
👉 Dans un datacenter local, souverain, maîtrisé, avec des humains.
🎯 Chez TAS Cloud Services, c’est exactement ce qu’on fait.
On ne vend pas de la magie.
On construit des infrastructures claires, solides, évolutives.
Et surtout, on les héberge dans nos propres datacenters, en France, en toute transparence.
Besoin d’un serveur dédié ? D'un cloud privé ? D’un accompagnement pour bâtir votre infra ? D’une équipe qui sait ce qu’elle fait depuis plus de 20 ans ?
Eh bien vous avez frappé à la bonne porte ! Et si vous voulez venir visiter… n'hésitez pas !
PS : Chez TAS, on a des éponges miracles en stock… pour nettoyer les architectures mal conçues. 🧽
Merci pour votre lecture.
Vincent.

Recevez notre veille sur l’actualité cloud / IT
La veille technologique est primordiale dans notre industrie. Nous vous faisons bénéficier des dernières actualités en la matière. Abonnez-vous à notre newsletter pour les recevoir chaque mois dans votre boîte e-mail.
S'inscrire à notre newsletter
Votre hébergeur de proximité
Externalisez votre informatique en toute sérénité avec TAS Cloud Services. Hébergeur cloud de proximité, nous vous accompagnons à chaque étape pour vous permettre de bénéficier d’une solution parfaitement adaptée à vos besoins IT.
Contactez-nous
Nous sommes là pour répondre à toutes vos questions et demandes de renseignements.
Votre hébergeur de proximité
A Sophia-Antipolis, France