
Crash informatique mondial : quand CrowdStrike et Microsoft provoquent le chaos
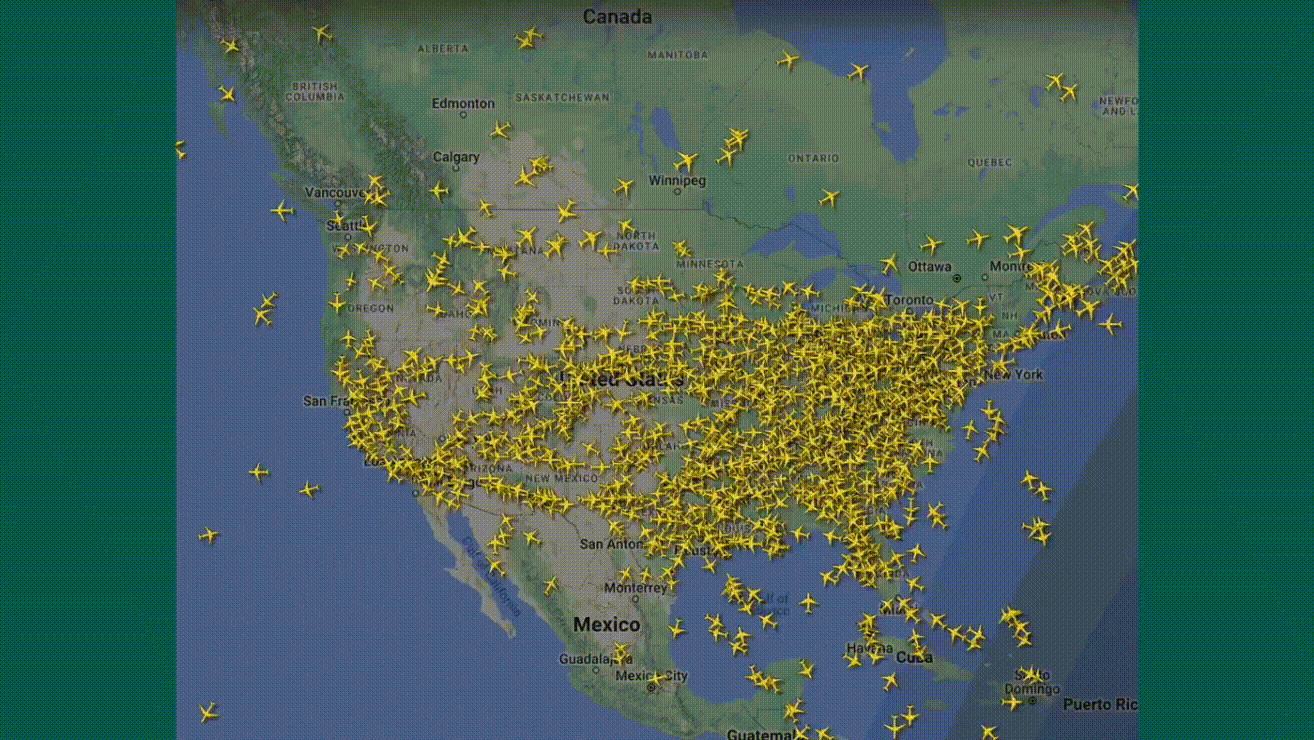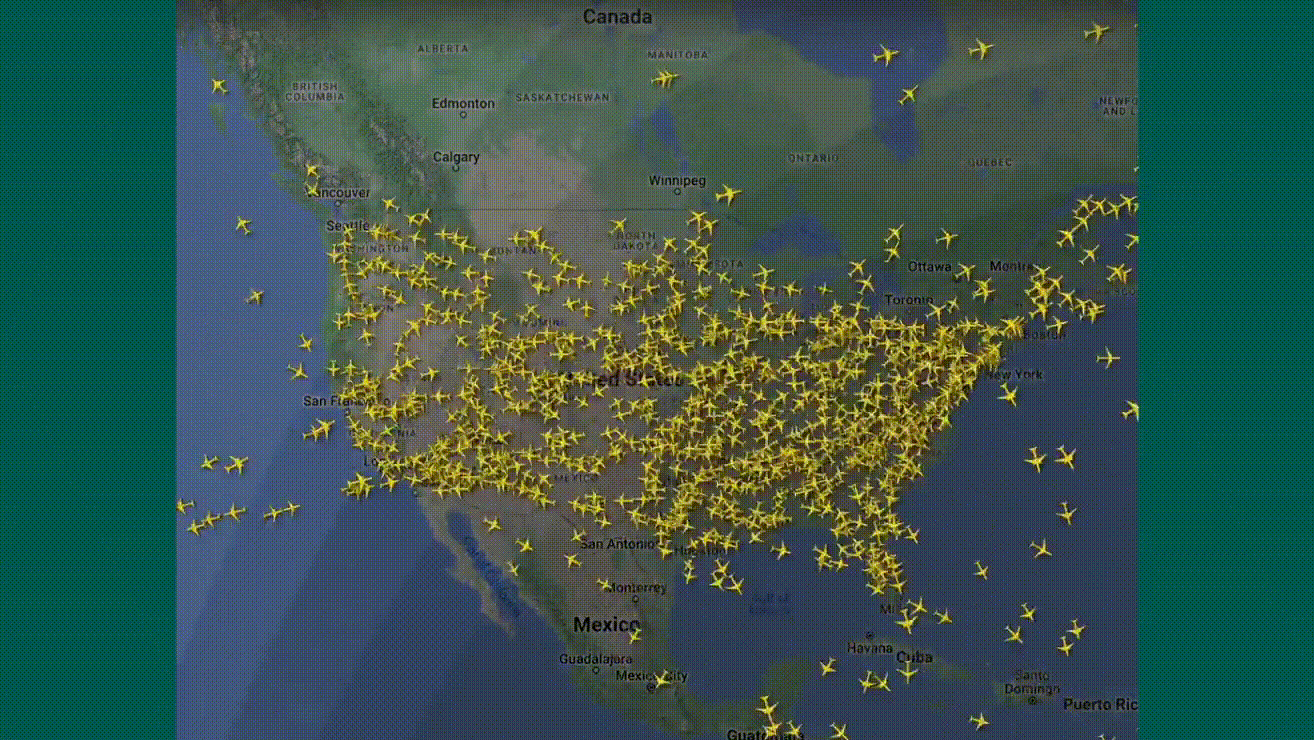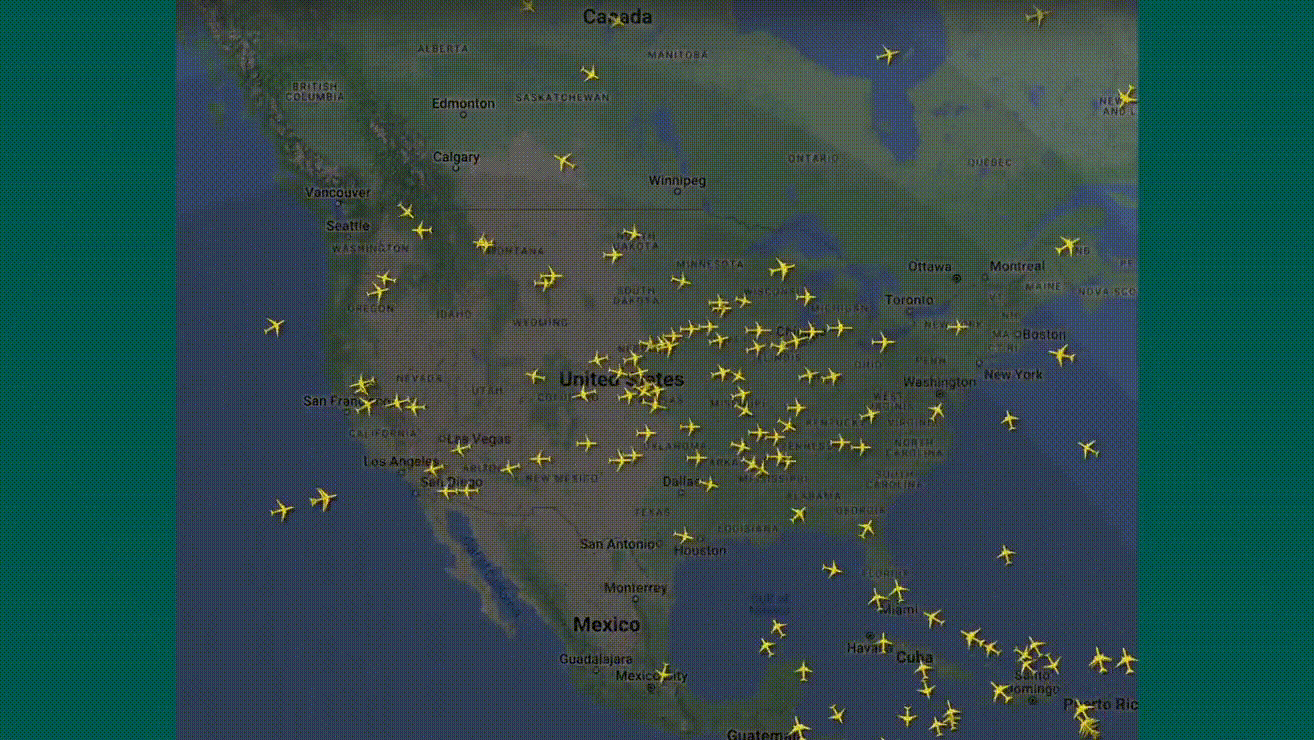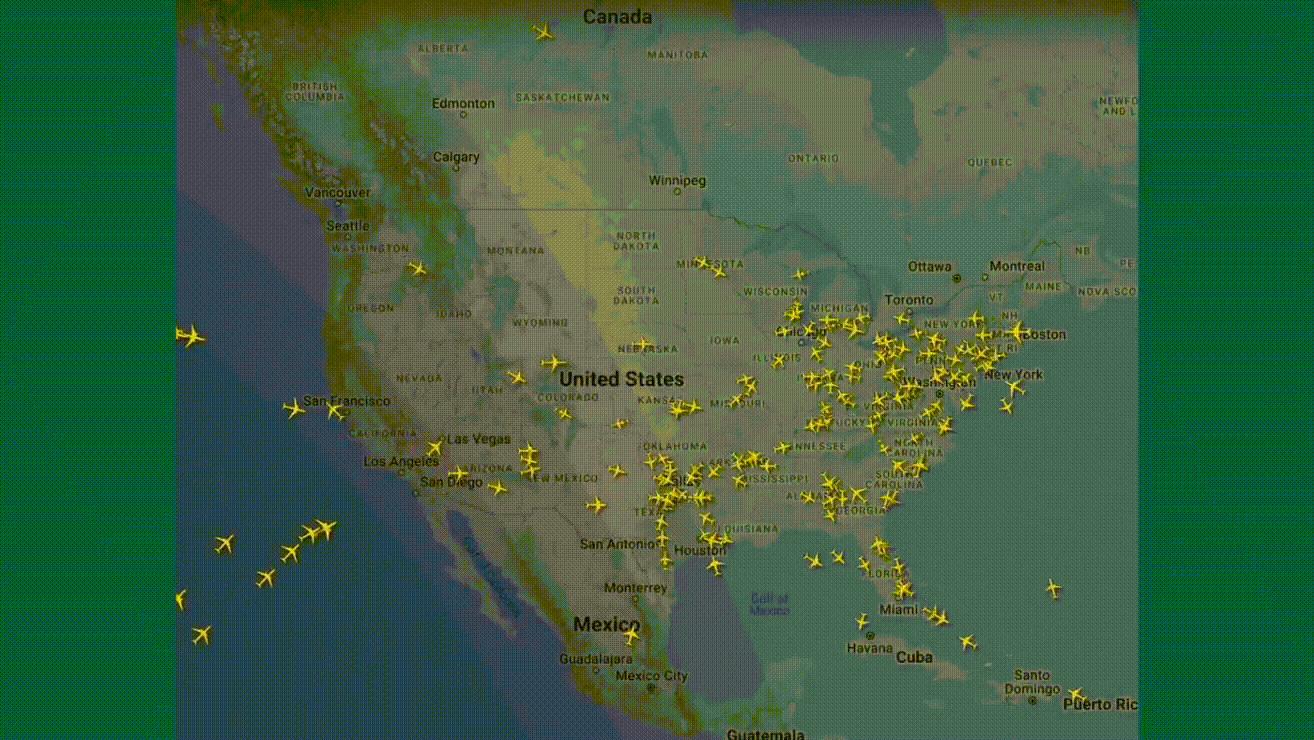
Le vendredi 19 juillet, nous avons été spectateurs d'une journée de folie ! Partout dans le monde, des écrans bleus à la chaîne : dans les bureaux, les hôpitaux, les aéroports... plus de 22 000 vols retardés ou annulés, même les tableaux d'affichage des vols étaient touchés. Imaginez la scène : des patients renvoyés, des avions bloqués au sol, et des banques complètement paralysées. Tout cela à cause d'une mise à jour défectueuse du logiciel antivirus de Crowdstrike.
Les pertes ? Déjà estimées à plusieurs dizaines de milliards de dollars. Mais pas de panique !
Ce n'est ni la fin du monde, ni la dernière crise informatique que nous vivrons. Allons voir ce qui s'est passé.
Microsoft ? Crowdstrike ? Un peu de contexte pour mieux comprendre
Microsoft et Crowdstrike, explication : les acteurs principaux
Il y a donc deux acteurs principaux dans cette histoire : Crowdstrike et Microsoft.
Je ne vais pas vous présenter Microsoft mais Crowdstrike oui
Né en 2011 aux USA, s'est rapidement fait un nom dans les logiciels de cybersécurité. Son produit phare, Falcon, utilise l'IA pour repérer les anomalies et bloquer les attaques avant qu'elles ne fassent des dégâts. le rôle d'un antivirus !
Mais malheuresement, en ce vendredi 19 juillet, une mise à jour est poussée et on connait la suite : des écrans bleus partout, des applications Microsoft 365 inaccessibles et le chaos dans les entreprises.
Pour l'anecdote : CrowdStrike et Microsoft sont à la fois alliés et rivaux. Leurs technologies fonctionnent ensemble,imbriquées, mais Microsoft propose également ses propres solutions de sécurité. On ne peut pas être juge et partie à la fois !
Cette panne montre à quel point nos systèmes sont désormais interconnectés. C'est comme si votre antivirus personnel plantait tout votre poste de travail. De quoi réfléchir à notre dépendance à ces géants…
Le contexte : que s'est-il passé le 19 juillet ?
Le vendredi 19 juillet, une mise à jour du logiciel a été déployée automatiquement sur les machines utilisant Windows. Cette mise à jour, censée améliorer la sécurité des systèmes, a au contraire causé une vague d'écrans bleus de la mort (BSOD).
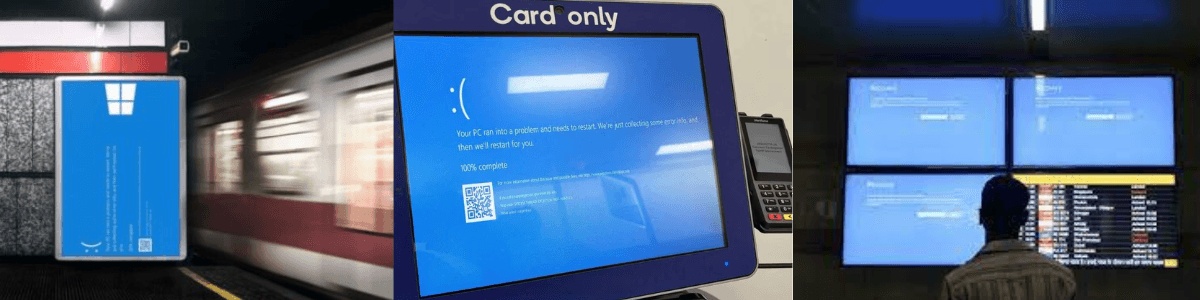
Crowdstrike est principalement utilisé dans les environnements d'entreprise, ce qui explique pourquoi les ordinateurs personnels n'ont pas été affectés de la même manière.
8,5 millions de machines (selon Microsoft) ont planté au même moment, causant des interruptions massives de services et des pertes estimées à plusieurs dizaines de milliards de dollars.
Allons plus loin et découvrons le problème en détail
Alors, qu'est-ce qui a causé cette avalanche d'écrans bleus ?
La mise à jour de Crowdstrike contenait un bug dans un "kernel driver". Mais c'est quoi un kernel driver ? Pour faire simple, c'est un logiciel qui fonctionne au cœur de l'OS, avec des permissions très élevées. Grossomodo, il a les mêmes accès que l'OS sur l'ordinateur. Donc, si ce logiciel en question bug … ça peut faire des dégâts.
A première vue, cette mise à jour a corrompu un fichier essentiel, le remplissant de zéros au lieu de son contenu prévu. Résultat : les machines ont commencé à planter dès le démarrage, affichant ce fameux écran bleu. Cette erreur au niveau du driver a nécessité un redémarrage complet des systèmes touchés. Comme le logiciel de Crowdstrike démarre en même temps que Windows, le bug empêchait les machines de redémarrer correctement.
Le plus gros problème ? Le redémarrage.
On en arrive au plus gros du problème, mais aussi la ou cela devient intéressant ! Même après un redémarrage, les machines continuaient à planter.
Pourquoi ? Parce que la mise à jour de Crowdstrike interférait avec le démarrage du système. Il y avait une "condition de course" : soit le composant de sécurité de Crowdstrike démarrait en premier et causait un crash, soit le système réussissait à récupérer la mise à jour correcte avant le crash. Une vraie loterie ! Bonne chance !
Les solutions principales proposées
La première solution proposée par Microsoft et Crowdstrike ? Redémarrer les machines encore et encore, jusqu'à 15 fois !
Oui, vous avez bien lu, 15 fois !!
L'espoir était qu'à un moment, le système récupérerait la bonne mise à jour avant que le bug ne provoque un nouveau crash. Mais cette méthode n'est malheureusement pas fiable pour tout le monde.
Et pour les entreprises touchées, c'était juste le début des galères. Pour les machines qui refusaient de redémarrer correctement, il faut une intervention manuelle. Les techniciens devaient démarrer les machines en "mode sans échec", où seuls les composants essentiels de Windows sont chargés. Dans ce mode, ils pouvaient accéder au fichier corrompu et le supprimer, permettant au système de récupérer la mise à jour.
Comment remettre en marche tous ces ordinateurs en panne ? Si vous êtes concerné, voici la marche à suivre pour ressusciter votre système en 5 étapes simples :
- Démarrez Windows en mode sans échec (appuyez sur F4 au démarrage).
- Une fois l'ordinateur allumé, allez dans le disque C:
- Cherchez le dossier C:\Windows\System32\drivers\CrowdStrike
- Supprimez le fichier qui commence par C-00000291 et se termine par .sys.
- Redémarrez l'ordinateur.
Plus d'information et de précision sur le Blog de Morten Knudsen à propos de Microsoft Security, Azure, M365 & Automation
Attention, il vous faudra probablement les droits d'administrateur pour faire ça. . Pour ceux qui ont eu la chance d'échapper à la panne, pas de stress. CrowdStrike assure que les postes non touchés ne le seront pas. Vous pouvez souffler. :)
L'enjeu pour les entreprises avec beaucoup de serveurs
Pour les entreprises possédant de nombreux serveurs, l'incident a été particulièrement problématique car il fallait intervenir manuellement sur chaque serveur affecté. Imaginez le temps et les ressources nécessaires pour redémarrer et réparer manuellement des centaines, voire des milliers de serveurs. Chaque serveur devait être démarré en "mode sans échec", et les fichiers corrompus devaient être supprimés un par un avant que le système puisse récupérer la mise à jour correcte.
Cette tâche est titanesque et a entraîné des interruptions a nécessité une mobilisation massive des équipes IT. Pour les grandes entreprises, le temps nécessaire pour redémarrer l'intégralité des services a considérablement impacté leur productivité et leur capacité à fournir des services critiques…
Analyse et réflexions : quelles leçons en tirer ?
Microsoft et l'Union Européenne : une histoire compliquée
Alors que le monde entier commençait à blâmer CrowdStrike pour la crise IT globale, Microsoft blame …. l'UE ! Pour rappel, en 2009, l'UE avait obligé Microsoft d'ouvrir l'accès au kernel de Windows à d'autres entreprises pour éviter un monopole. Cela a notamment permis à des entreprises comme CrowdStrike de développer des solutions de sécurité.
Mais est-ce que Microsoft ne profiterait pas de la crise pour rappeler que sans cet accès au kernel, cette panne n'aurait peut-être pas eu lieu ? Cette stratégie semble opportuniste et détourne l'attention des véritables responsabilités.
Habile mais quelque peu opportuniste. Voici quelques vraies propositions qui peuvent faire avancer :
Ne pas mettre tous ses oeufs dans le même panier :
La dépendance à un seul fournisseur de solutions critiques peut augmenter les risques. Diversifier les fournisseurs et les solutions permet de réduire ces risques et d'assurer une meilleure résilience face aux pannes.
Des procédures de fonctionnement en mode dégradé :
Il est crucial pour les entreprises de prévoir des procédures de fonctionnement en mode dégradé. Cela inclut des plans d'urgence pour continuer à fonctionner en cas de panne majeure, ainsi que des solutions de sauvegarde et de reprise après sinistre.
Solutions pour une continuité d'activité :
Il est facile de donner son avis après les événements, et nous ne voulons jeter la pierre à personne, mais il serait intéressant d'aller plus loin et de comprendre quelles solutions auraient dû être mises en place.
Reprise d'activité en mode dégradé sur Linux :
Cela aurait permis d'utiliser des systèmes d'exploitation alternatifs comme Linux et aurait pu contourner ce blocage ou du moins en réduire l'impact.
Les GAFAM ne sont pas la panacée à tous les maux.
Ils ont des problèmes comme tout le monde. Cet incident nous rappelle l'importance de repenser notre dépendance aux solutions des géants technologiques et de mettre en place des infrastructures IT résilientes et diversifiées.

L'incident de Crowdstrike et Microsoft nous rappelle que même les meilleures entreprises peuvent rencontrer des problèmes. Ce n'est ni la fin du monde, ni la dernière crise informatique que nous vivrons. En diversifiant nos solutions, en adoptant des pratiques rigoureuses de gestion et de test, nous pouvons minimiser les risques et garantir la continuité des opérations dans toutes les industries.
Pour aller plus loin
Maintenant, pour ceux qui veulent plonger un peu plus profondément dans ce qui s'est passé techniquement...
Pour aller plus dans le détail, certains enqueteurs estiment que le problème est dû à un bug dans le code impliquant un "pointeur NULL". Pour faire simple, le programme aurait tenté d'accéder à une adresse mémoire non valide (0x9c), ce qui conduit à un crash du système. Ce type de bug est courant dans les programmes écrits en C++, où l'adresse "0" indique l'absence de valeur. Si le programme tente de lire cette adresse sans vérification préalable, une erreur critique peut se produire, comme cela semble avoir été le cas ici
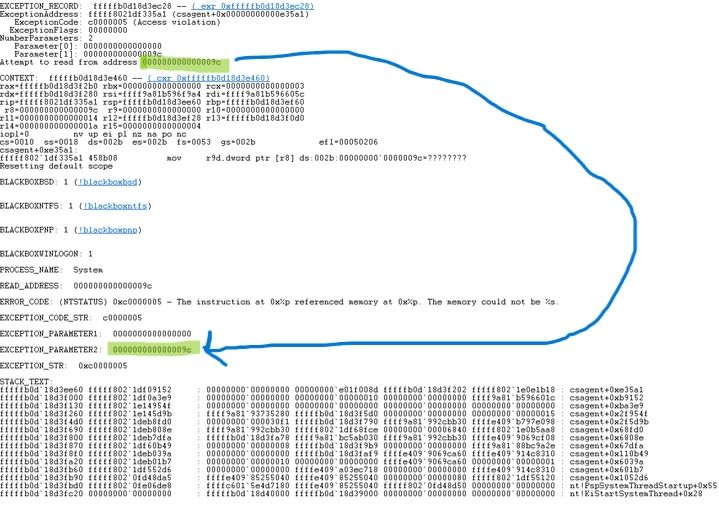
Cependant, d'autres sources et des experts techniques ont contesté cette explication, affirmant qu'il ne s'agissait pas d'un bug de pointeur NULL. CrowdStrike a également démenti cette hypothèse via son site officiel, précisant que le problème n'était pas lié aux octets nuls contenus dans le fichier de canal 291 ou tout autre fichier de canal. Selon ces démentis, le problème pourrait provenir d'autres aspects techniques du logiciel, qui nécessitent encore des investigations plus approfondies pour être entièrement compris.
Rappelons-nous, même les meilleurs peuvent faire des erreurs, et c'est une occasion d'apprendre et de s'améliorer.
Affaire à suivre !
[MAJ] Pour aller plus loin :
Microsoft a un programme de certification des drivers nommé WHQL. C'est un peu comme le label de qualité pour les pilotes, et chaque driver a une propriété indiquant s'il doit être chargé au démarrage ou non. Dans le cas de CrowdStrike, cette propriété était configurée pour être chargée au démarrage.
Le driver de CrowdStrike était certifié par Microsoft, mais voilà le hic : les règles de sécurisation changent fréquemment, et re-certifier un driver est un processus long, complexe et coûteux. Pour éviter cette galère, CrowdStrike a eu l'idée d'écrire leur driver sous forme d'un interpréteur de p-code. En gros, ce driver utilise un autre fichier, qui n'a pas besoin d'être certifié, pour exécuter ses tâches.
C'est ce fichier non certifié qui a été corrompu, et comme le driver tourne au niveau du kernel, cela a causé le fameux écran bleu de la mort. Ce qui aurait été un plantage mineur d'une application s'est transformé en véritable cauchemar.
Cette méthode de CrowdStrike, bien que compréhensible d'un point de vue opérationnel, soulève de sérieuses questions sur la sécurité. La "security through obscurity" n'est jamais une bonne stratégie. Utiliser un interpréteur de p-code non certifié pour contourner les re-certifications peut sembler malin, mais cela expose à des risques majeurs en cas de faille.
On peut imaginer mieux… Il suffirait de changer le fichier programme pour obtenir un accès très privilégié à l'OS. Cela signifie qu'un acteur malveillant pourrait exploiter cette méthode pour accéder au système avec des privilèges élevés, ce qui est extrêmement dangereux. CrowdStrike ne doit pas être très heureux que cette méthode soit maintenant connue, car elle pourrait être exploitée par des hackers. Beaucoup de responsables IT vont probablement revoir leurs procédures de sécurité après cette révélation.

Recevez notre veille sur l’actualité cloud / IT
La veille technologique est primordiale dans notre industrie. Nous vous faisons bénéficier des dernières actualités en la matière. Abonnez-vous à notre newsletter pour les recevoir chaque mois dans votre boîte e-mail.
S'inscrire à notre newsletter
Votre hébergeur de proximité
Externalisez votre informatique en toute sérénité avec TAS Cloud Services. Hébergeur cloud de proximité, nous vous accompagnons à chaque étape pour vous permettre de bénéficier d’une solution parfaitement adaptée à vos besoins IT.
Contactez-nous
Nous sommes là pour répondre à toutes vos questions et demandes de renseignements.
ONLINE 93 - La newsletter de TAS Cloud Services - Janvier 2025
Votre hébergeur de proximité
A Sophia-Antipolis, France